3. Machine Semiosis
This chapter compares the key components of machine semiosis with those of human semiosis and shows how the parameters of machines are coupled to, and thereby made to align with, the values of people. By offering a gentle introduction to the mathematics underlying such models, I aim to dispel some of the mystery—and magical thinking—that otherwise surrounds them.
“The signs and interpretants of language models relate to something outside of themselves, and thereby possess intentionality, by virtue of being parasitic on a more originary mode of human intentionality.”
Large Language Models
At a certain level of abstraction, a large language model may be understood as a parameter-dependent function that accepts a sequence of words as its input and returns a sequence of words as its output. Assuming the function was well chosen and its parameters have been adequately set, the inputted sequence, known as the prompt, specifies a task that the user wants fulfilled, and the outputted sequence, known as the response, fulfills that task.
For example, if the prompt is “alphabetize the following words: bat, dog, cat, zebra, armadillo,” the response could be “armadillo, bat, cat, dog, zebra.” If the prompt is “translate the following sentence into English: me llavo las manos,” the response could be “I wash my hands.” If the prompt is “what is Napoleon most famous for?,” the response could be “conquering much of Europe.” And if the prompt is “write a short story, in the style of Chekhov, involving three clowns and a cabbage,” the response would be just such a story. Other actions a large language model may be asked to undertake include offering lifestyle tips, writing algorithms, brainstorming, extracting evidence from texts, and the like.
Recursively, and more generally, if the human user inputs a discursive move, the language model can output a felicitous response to that move, which can itself constitute a discursive move calling for its own response (recall the example of semiotic enchaining), such that a language model can engage in human-like conversations. This is what puts the Chat in ChatGPT.
More carefully, the prompt is typically a sequence of words that describes, and perhaps demonstrates, certain satisfaction conditions, and the response— at least when all goes well—is a sequence of words that satisfies those conditions. Phrased another way, if prompts are descriptions of actions that the user wants the model to undertake, responses are the results of the actions so undertaken.
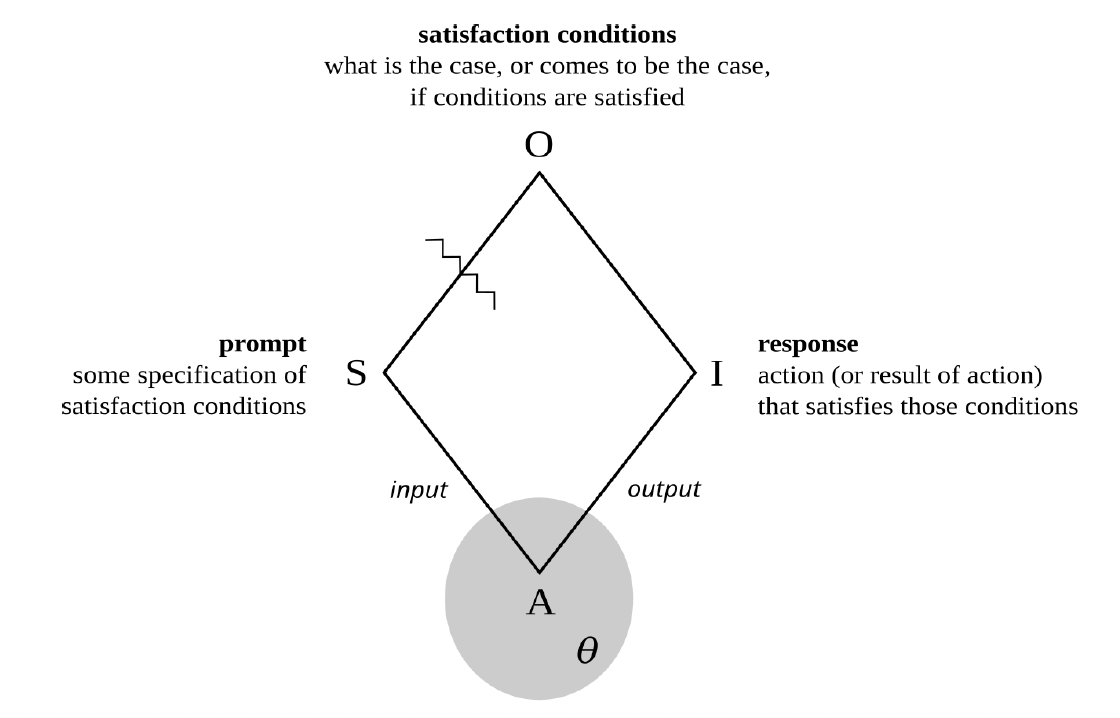
Figure 4. Machine semiosis
In short, at this level of abstraction large language models are very complicated semiotic agents, with prompts as their signs, responses as their interpretants, satisfaction conditions as their objects, and parameters rather than values as their guiding principles. See figure 4 (and recall figure 1).
But unlike the example of human semiotic agents discussed in the preceding chapter, such models really are mathematical functions. And so, rather than saying that a machinic agent senses signs and instigates interpretants, it is better to say that such an agent accepts signs as inputs and returns interpretants as outputs. Its output depends not just on its input but also on the mathematical details of the function in question, as well as the particular numerical values of all its parameters.
In a certain sense, then, a large language model is simply a mathematical function that behaves in a human fashion. How was it disciplined to do so?
Such a movement from prompt to response, which involves the calculation of a function’s output when given an input (and already established parameter values), is known as forward propagation. It may be summarized as follows:
I = Aθ(S)
But before a language model can respond to prompts in a way that satisfies the desires of its users, its parameters (θ) must be set. This means determining good values for potentially trillions of variables by training the model to undertake certain carefully chosen tasks. The model is repeatedly given various inputs, and the values of the parameters are slowly adjusted, through an algorithmic process known as backpropagation, until the outputs relate to those inputs in a way that is deemed adequate for the tasks in question.
While there are many such tasks, two stand out in terms of their overall importance for a large language model like ChatGPT. In a process known as pretraining, the model is given sequences of words from a huge corpus of human-authored texts and asked to predict the next word in the sequence. Such training gives language models their distinctive ability to produce next words, conditioned on prior words, and thereby to generate sequences of words, or texts, that seem formally cohesive and functionally coherent. This is what puts both the P and the G in ChatGPT.
In short, pretraining a machinic agent to mirror the actual makes it good at generating the plausible.
Language models are surprisingly capable with only pretraining (given enough parameters, training data, and computational effort), but the word sequences outputted only really relate to the word sequences inputted as textual continuations. For that is all the models were trained to produce. To make the outputs consistently relate to the inputs as responses to prompts, and hence as the semiotic satisfaction of the stated conditions (as described above), fine-tuning must take place.
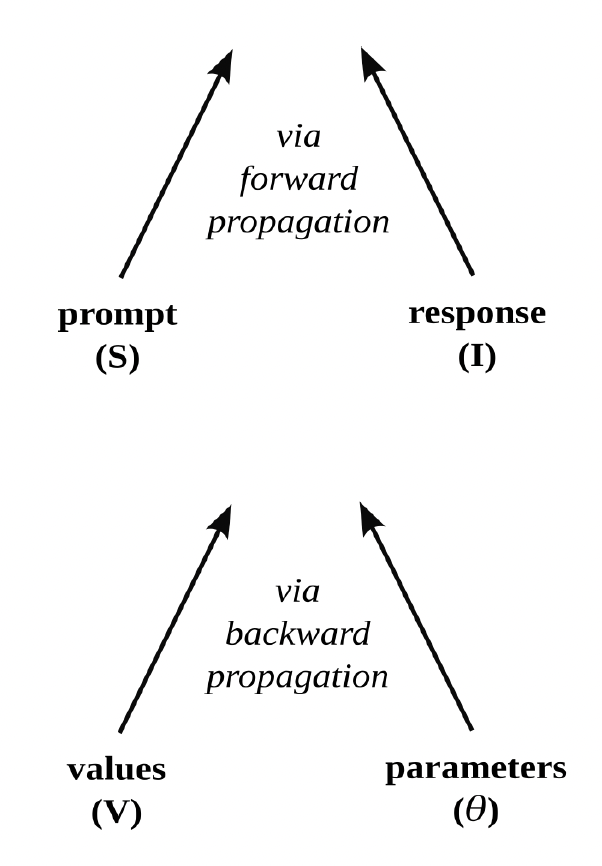
Figure 5. Two modes of alignment
While there are many varieties of fine-tuning, the most important kind is arguably reinforcement learning with human feedback. It involves several steps. First, human judgments are used to rank possible responses to various prompts in terms of their relative preferability (given some standard of values). For example, which of two responses is considered more helpful, truthful, and harmless? Second, those rankings are used to train a second language model (known as a “reward model”) to output numerical scores consistent with those rankings when given prompt-response pairs as inputs. That is, a reward model is trained to numerically mirror human preferences regarding the relative helpfulness, truthfulness, and harmlessness of responses. Third, the outputs of this second language model are used as a reward mechanism, or feedback signal, to further train the original model (that was initially pretrained to engage in next-word prediction), such that the responses it produces better satisfy the prompts of its users. Just as a machine learning algorithm may be trained to play a video game (by acting on its environment in a way that maximizes its score), a language model is thereby trained to play language games (by responding to users’ prompts in a way that maximizes its reward).
In short, for machinic responses to align with human prompts during forward propagation, machinic parameters must be made to align with human values during backpropagation (through pretraining or fine-tuning). See figure 5.
Slashing Words from Worlds
Recall, from chapter 2, that slashes separate signs from objects, and hence something like the perceived from the intuited, what is present from what is absent, or what is given from what is inferred. Language models involve many such slashes. At a relatively high level of abstraction, as was shown in figure 1, the slash between sign and object separates prompts from satisfaction conditions, or speech acts from communicative intentions. At a lower level of abstraction, as seen in the context of next-word prediction during pretraining, the slash separating sign and object separates earlier words from later words, and hence something like the past from the future.
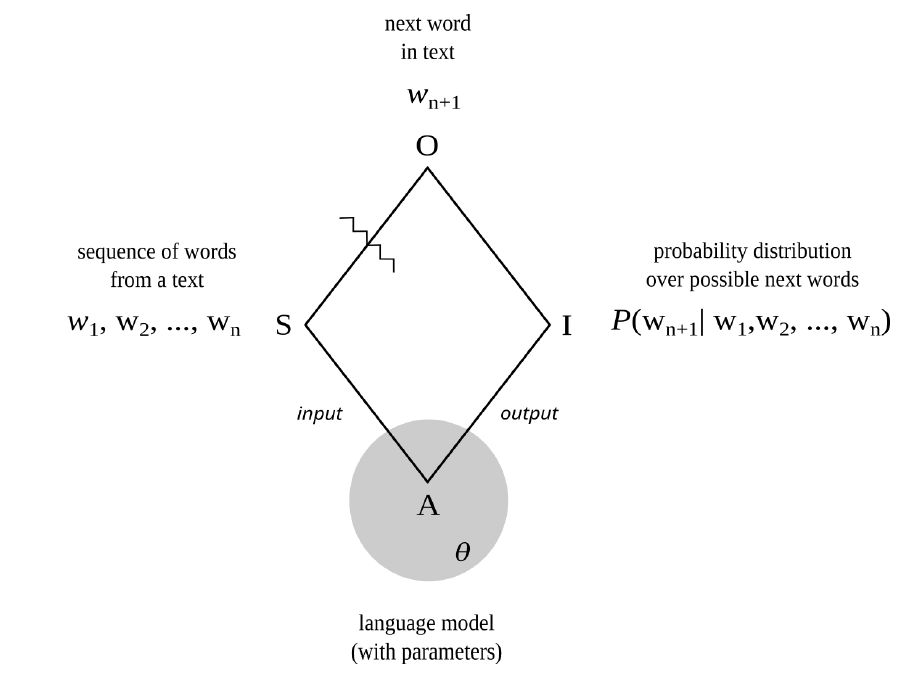
Figure 6. Next-word prediction as semiotic process
In particular, next-word prediction, itself a key part of response formulation, is also a semiotic process. See figure 6. The sign is a sequence of words from a human-authored text. The object is the actual next word in the sequence (as it occurs in the text). And the interpretant is a probability distribution over possible next words (conditioned on the preceding words).
At this level of abstraction, the slash separating sign and object, and hence that which separates what is given from what must be inferred, is not the kind of slash that separates representations from the world, appearance from identity, performance from competence, action from intention, or words from things (as stereotypically understood). It is, rather, the kind of slash that separates the future from the past, or earlier parts of texts and scores from later parts. And hence it turns on interpretive grounds that are similar to those that govern musical expectations and poetic prefigurings, such as repetition, parallelism, meter, echos, and refrains.
Positively framed, predicting what comes next, given what has come before, is the fundamental capacity of such machinic agents. Negatively framed, large language models traffic in word-word relations, not word-world relations.
As will be seen in later chapters, this positioning of the slash both animates and haunts such agents.
Parasitic Intentionality
By referring to such language models as semiotic agents, I am not trying to project sentience or sapience, or any other aspect of human subjectivity, onto them. Rather, I am simply foregrounding the fact that such models are capable of engaging in what seem to be complicated acts of semiosis and embody (in their functional architecture and numerical parameters) a mode of intentionality that is derivative of their makers.
In particular, large language models are mathematical functions that serve instrumental functions derived from the purposes of the human agents who created and trained the models in question (such that a model’s interpretants of particular signs, qua outputs, come to more and more closely resemble human interpretants of the same signs).
Indeed, the intentionality (or object-directedness and ends-directedness) of the trained model is derivative not just of the intentionality of the humans who trained it (insofar as they want to make a machine that serves a certain instrumental function by creating a machine that calculates a certain mathematical function) but also of the intentionality of the humans who produced the texts and instructions it was trained on (such as corpus data, prompt-response pairs, preferability judgments, and alignment criteria).
In this sense, the signs and interpretants of language models relate to something outside of themselves, and thereby possess intentionality, by virtue of being parasitic on a more originary mode of human intentionality (which is itself derivative of processes like natural selection, not to mention education, enculturation, and indoctrination).
That said, I will later investigate why it is so easy, and perhaps alluring, to project complex capacities like consciousness and choice onto such agents, so that they might come to be not just personified but also fetishized, and perhaps even deified, by unsuspecting human agents.