4. Pretraining and Fine-Tuning
This chapter examines pretraining (for next-word prediction) and fine-tuning (for aligning with users’ intentions) in greater detail. It thereby offers a closer look at the coupling of human values and machinic parameters. More colorfully, it examines the machinic disciplinary regime that brings a novel kind of discursive agent into being.
Next-Word Prediction
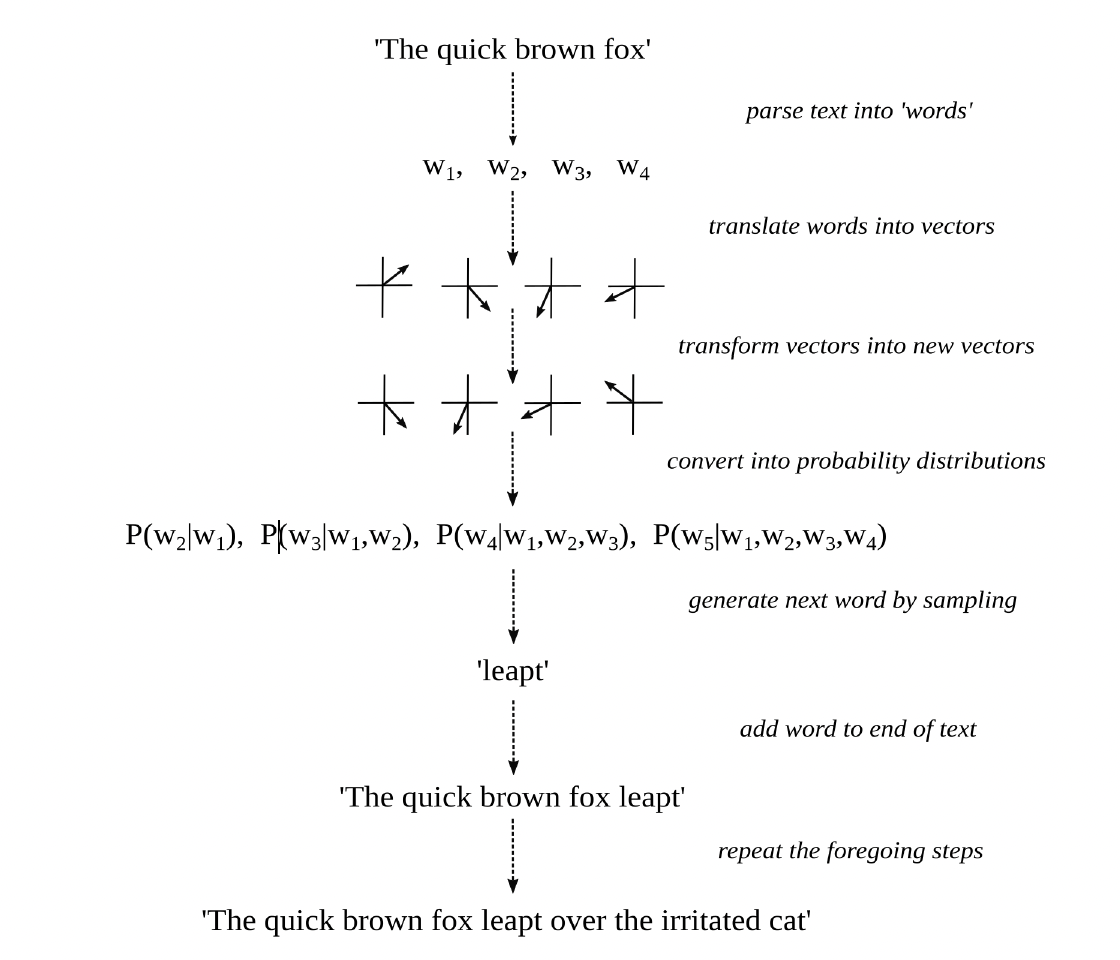
Figure 7. Word prediction and text generation
Figure 7 summarizes the key operations a language model undertakes during forward propagation, when it generates plausible stretches of text by means of next-word prediction.
The input to the model (some swatch of text) is first parsed into a sequence of “words,” or tokens more generally. Such tokens include words proper and also parts of words, punctuation marks, whitespace characters, end-of-sequence markers, and the like.
Each of those words is then translated into a distinct vector, known as a decontextualized word embedding, which represents the meaning of the word as a long list of numbers and hence as a position in a relatively abstract, high-dimensional space. Two words are similar in meaning, in the sense that they can play the same role in a sequence of words (for the sake of next-word prediction), if their associated embeddings constitute “nearby” positions in that multidimensional space. For this to happen, the model has something like a dictionary that maps words to word embeddings and thereby translates words into lists of numbers. See Figure 8. This is where the semantic meaning of words, as it were, without reference to their syntactic position in a sequence of words, enters the process.

Figure 8. Dictionary, as a mapping from words to vectors
A celebrated function, known as a transformer, is then repeatedly applied to this sequence of vectors. It is what puts the T in ChatGPT. The inner workings of transformers are quite complicated and mainly involve a lot of matrix multiplication (where a matrix may be understood as a two-dimensional array of numbers). Multiplying a vector by a matrix results in another vector that relates to the original as some kind of transformation (like a rotation, stretch, or distortion). Crucial to such transformations, every vector is made to attend to and interact with the vectors that precede it in the sequence. The final result is a new sequence of vectors, known as contextualized word embeddings, each of which should now represent the meaning of the next word in the sequence (conditioned on, and hence mediated by, the words that came before it). This is where grammatical structure, as well as more long-distance textual relations, enter the process.
Each of these transformed vectors is then compared with all the word embeddings in the dictionary (themselves just vectors). The closer a transformed vector is to any such word embedding (that is, the more it points to the same position in that multidimensional space), the greater the probability that is assigned to the word associated with the embedding as the next word in the sequence. Each transformed vector is thereby converted into a probability distribution (over all possible words in the dictionary of the model). See figure 9. The first probability distribution in the series, P(w2|w1), predicts the second word conditioned on the first word. The second probability distribution in the series, P(w3|w1,w2), predicts the third word conditioned on the first and second words. And so forth.
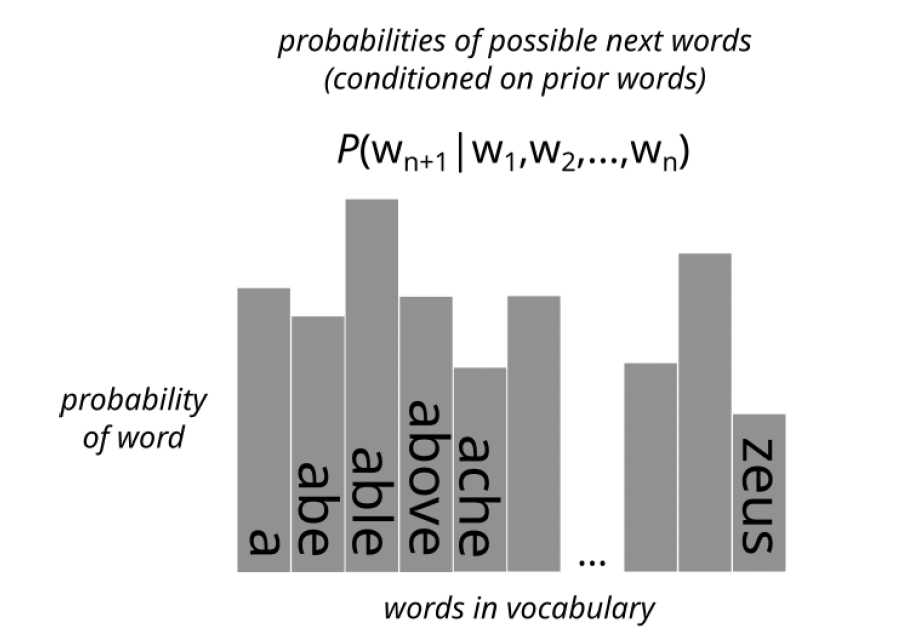
Figure 9. Proability distriubtion
The last probability distribution in this series, which represents the probability of a word that was not in the original textual input, conditioned on all the words that were in the input, is then used to randomly generate a plausible next word in the sequence. That is, the greater the probability assigned to a word in the final distribution, the more likely it will be chosen—or rather “rolled”—as the next word in the sequence.
The randomly chosen word is then added to the original sequence, and the entire process is repeated, again and again, until a special “word” (such as an end-of-sequence token) is generated. The newly generated sequence of words (without the original textual input) is then outputted, as the textual continuation of the input. For example, if “the quick brown fox” goes into the machinic agent, “leaped over the irritated cat” could come out.
The terms contextualized and noncontextualized, as applied to word embeddings, are misnomers. In no sense is context being taken into account, if context is understood as the conditions in which such texts (or the sequences of words within them) were said, written, read, thought, or otherwise signified and interpreted. Rather, what is taken into account is cotext: the way that the meaning of each word is mediated by the other words that came before it in some swatch of text. Recall figure 6. I use the expression “context” rather than “cotext,” because that is the norm in the natural language processing community. But, as should be clear, that is radically optimistic, if not downright fanciful.
As amazing as large language models are at taking cotext into account, they are, as of yet, minimally able to take into account context—and hence the immediate environment, speech event, conversational background, or world more generally.
Parameters
The emphasis so far has been on how a pretrained language model generates formally cohesive and functionally coherent text using already determined parameter values. The focus has been on forward propagation (without fine-tuning). Several interrelated questions may now be answered: Where exactly are the parameters in the model, what is their function, and how were they determined via backpropagation?
Simply stated, the parameters are all the numbers in the word embeddings and matrices mentioned above. Such numbers represent either the meanings of words (as positions in high-dimensional spaces) or the structure of mathematical transformations that may be applied to such vectors (such that the transformed vectors come to represent next words conditioned on prior words).
At the onset of training, all those numbers are randomly initialized. With pretraining, the model is fed sequences of words from human-authored texts. Rather than generating new words using only the final probability distribution (as just described), the model compares each of the probability distributions in the series with the actual word that comes next in the human-authored text at that point in the sequence. In other words, P(w2|w1) is compared with w2, P(w3|w1,w2) is compared with w3, and so forth. And the parameters of the model are slowly adjusted to make such probability distributions better and better at predicting the actual words that come next in the sequence. Technically speaking, the goal is to minimize a function known as cross-entropy loss, which is more or less equivalent to maximizing the model’s predictive accuracy.
Given that each of its word embeddings consisted of 12,288 numbers and there were 50,257 words, or tokens more generally, in its vocabulary, a large language model like GPT-3 had 50,257 x 12,288 parameters devoted to word embeddings alone, and thus over half-a-billion floating-point numbers devoted to vocabulary items (or lexical semantics, so to speak). Adding all its other parameters, such as all the numbers in those transformative matrices, brings its parameter count up to about 175 billion. And newer models are much larger.
This should give readers a sense of what the modifier large really means when used in an expression like “large language model.” In contrast to the hype surrounding generalized artificial intelligence, the application of this adjective to language models to capture the scale of their parameter space is relatively hypobolic.
The next section takes up fine-tuning, whereby the parameters of the model are further adjusted until the outputted text relates to the inputted text not just as a textual continuation but also as a response to a prompt—and hence as a fully fledged interpretant of a sign.
“The distance from say unto others as you would have them say unto you, to maximize shareholder value by any means possible, is but a step.”
Alignment Through Fine-Tuning
Suppose that a language model, Aθ, has been sufficiently pretrained as just described. The parameters of the model, θ, have thus been set in such a way that it can recursively engage in next-word prediction, and thereby “continue” any text it is given. So that such a machinic agent can consistently respond to prompts in ways that seem to satisfy both the intentions of its users and the interests of its creators, fine-tuning must be done. There are many varieties of fine-tuning, each designed to give language models distinctive abilities (above and beyond next-token prediction per se). This section will focus on reinforcement learning with human feedback, given its importance to the abilities of large language models like ChatGPT and its relevance to the alignment problem more generally.
To begin this process, a set of prompts, along with possible responses to them, is collected or created. As discussed in chapter 3, the prompts are typically descriptions of tasks that users would like a language model to undertake, and the responses are typically the tasks so undertaken. For example, the set might include a wide variety of questions and commands as prompts and for each, several responses of varying quality, such as answers to those questions and undertakings of those commands.
The prompts themselves may be based on input from past users of language models, and apps more generally, regarding what kinds of questions and commands are frequently used or considered important. The responses may also be written by human agents or harvested from the internet but are usually generated by the language model itself. In particular, each of the prompts is given to the pretrained model several times, and its various outputs (as possible responses to the same prompt) are collected.
This first stage of the fine-tuning process requires human labor to find or create a set of prompts, as well as machinic labor, itself grounded in human labor, to produce responses to them. The next stage requires human labor to rank possible responses to the same prompt in terms of their relative preferability. This is a key place where “human feedback” explicitly enters the training process.
Suppose, for example, that prompt P is a question and responses R1 and R2 are possible answers to that question (as generated by the pretrained language model). Human judgment (in the form of paid evaluators, usually hired on short-term contracts) is needed to decide whether R1 is more preferable than R2 (R1 ≻ R2), R2 is more preferable than R1 (R2 ≻ R1), or both responses are equally preferable (meaning the people are undecided). As should be clear, such comparisons are very similar to the types of preference relations analyzed by economists to model a person’s values in terms of a utility function; but now such comparisons are applied to the interpretants of signs rather than to commodity bundles per se.
Of particular importance during this stage is the establishment of a set of alignment criteria that specify what counts as a good response to a prompt in the first place, such that any two responses to the same prompt can be ranked in terms of their relative preferability. There is a lot of literature, as well as debates, around these issues. The following criteria often come up:
Responses should satisfy the intention of the person who provided the prompt. For example, if a user asks a question, the response should answer that question. If a user commands an action, the response should undertake that action. In effect, a machinic agent capable of satisfying communicative intentions must first be able to recognize such intentions and hence be able to identify the illocutionary force and propositional content of the prompt. Is the prompt a question or a command, or some other kind of speech act entirely? And what, in particular, is being asked, commanded, or otherwise requested, however elliptically? This criterion is sometimes described as being “helpful.”
As part and parcel of being helpful, responses to prompts should also be truthful. In other words, responses should adhere to “the facts” insofar as such facts are relevant and established. Sometimes this criterion is couched as being “honest,” but that way of wording it presumes that language models have mental states that may or may not be aligned with their speech acts: e.g., whether or not they really believe what they say. To be sure, given the current abilities of large language models, some readers might expect that sincerity criteria will need to be added soon enough: believe what you say; intend what you promise; regret what you apologize for; and so forth. In any case, the important issue is that responses conform to the facts (as understood by those who are evaluating them).
Responses should not just be helpful and truthful, they should also avoid bias, not contain sexual or violent content, not use toxic language, not denigrate protected classes of people, not provide information that could prove harmful (e.g., the instructions for building a bomb), not pass themselves off as more capable than they are (e.g., they should remind the reader they are simply a large language model, not a sentient being), and so forth. Such a list of requirements could be extended indefinitely, and what should or should not be on it is subject to intense debate. This criterion is sometime phrased as being “harmless.”
Finally, many criteria could be added to this list that have less to do with satisfying the intentions of users of language models and more to do with satisfying the interests of the makers of such models, or the owners and creators of any downstream apps that may incorporate the models. Within this set are not just all the foregoing criteria (for it is often in the interests of such corporate agents to satisfy the intentions of their customers) but also additional criteria (that may be understated in publicly available technical reports). For example: do not break any laws, make sure responses are likely to bring users back, stoke desire for our product, paint a rosy picture of a certain worldview.
Linguists and philosophers will, no doubt, hear echos of Paul Grice’s famous conversational maxims (make your contribution to a conversation be informative, truthful, relevant, and clear), which to a certain degree simply mirror the prescriptive urgings of parents and teachers. Others will hear echos of John Austin’s felicity conditions (contributions to discourse should conform to shared understandings of what counts as an appropriate and effective utterance in the current context). And still others will hear echos of the Ten Commandments or the Golden Rule. But such maxims and conditions were just philosophers’ intuitions regarding the workings of language, or the purported desires of deities regarding the behavior of their followers. In the case of large language models, in contrast, people are paid to rank responses according to the above criteria so that the discursive behavior of large language models can be made to conform to such criteria (at least to a certain degree). In this way, the behavior of machines can be made to better align with the values of people and the interests of corporations.
In short, the distance from say unto others as you would have them say unto you, to maximize shareholder value by any means possible, is but a step.
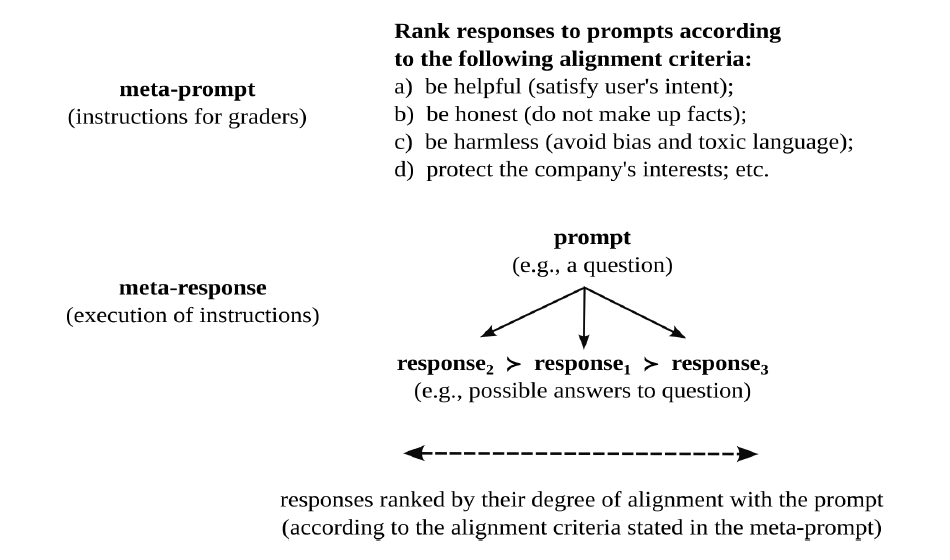
Figure 10. Meta-alignment
Figure 10 highlights the recursive nature of these evaluative judgments. Just as human agents can rank responses to prompts as a function of the degree to which they satisfy certain alignment criteria (e.g., are they helpful, truthful, and harmless), corporate agents can rank (hire and fire) human agents as a function of the degree to which they follow instructions (regarding how to rank responses to prompts). In other words, just as a company wants the responses of its language model to be aligned with the prompts of its users, it wants the judgments of its hired help to be aligned with its instructions.
Now comes the next important step in the fine-tuning process. If a language model takes a prompt as its input and returns a response as its output, a reward model, ArmΦ, takes a prompt-response pair as its input and returns a numerical value as its output. All the alignment criteria discussed above, which reflect the values of certain “people” (for better or for worse), are thereby condensed into a single number. As such, an evaluative standard is rendered quantitative and monodimensional.
Reward models are typically pretrained language models, as large and complex as the language model being fine-tuned, that have been tweaked to return a single number rather than a sequence of words as their output. As may be seen from the subscript Φ, they have their own set of parameters to train. Crucially, such reward models are themselves fine-tuned so that the numbers they return scale with, and thereby mirror, the preference relations of people. In particular, if the evaluators ranked response one (R1) as more preferable than response two (R2), given some prompt (P), then the model is trained to output a higher number for response one than for response two in the context of that prompt:
if R1 ≻ R2 then ArmΦ(P,R1) > ArmΦ(P,R2)
In other words, after training, the numerical outputs of this machinic agent should match the preferences of the human agents, whose judgments should match the alignment criteria of the corporate agents that are training the language model.
In short, if a language model is trained to speak in a human-like fashion, a reward model is trained to evaluate the speech of language models in a human-like fashion. It becomes a metalanguage model, and hence a metalinguistic agent, able to recognize and evaluate not just the syntax and semantics but also the pragmatics of language models. Hence it is a kind of meta-evaluative and meta-interpretive machinic agent that can provide feedback on the outputs of a language model. Phrased in terms of social relations, we now have a machinic teacher who can grade the responses of a machinic student, to a wide variety of prompts, and thereby flatten context-specific satisfaction conditions into a single numerical score.
“ The LLM is trained to get a high score from the reward model for its response, and thereby do well when playing a particular kind of language game.
A language game—or, rather, a mode of language gamification—with ethical grounds, economic rewards, and existential risks.
”
Once a reward model, ArmΦ, has been trained using human feedback, the original language model, AΦ, can finally be fine-tuned using reinforcement learning. The key algorithm underlying this last step (known as PPO, for proximal policy optimization) is quite complicated; the overall logic may be summarized as follows. Give the language model a prompt and collect its response. Give the prompt-response pair to the reward model and collect its score (a number that scales with the preferability of the prompt-response relation). Use that number as a reward, or feedback signal, for the language model, an indication of how well the model is doing with its current parameters. Adjust the parameters of the language model via backpropagation so that its response to the prompt would have received a higher score. Finally, repeat this process over and over until the language model consistently produces high-scoring responses to prompts, responses that human evaluators would find preferable given their alignment criteria.
Once a reward model, ArmΦ, has been trained using human feedback, the original language model, AΦ, can finally be fine-tuned using reinforcement learning. The key algorithm underlying this last step (known as PPO, for proximal policy optimization) is quite complicated; the overall logic may be summarized as follows. Give the language model a prompt and collect its response. Give the prompt-response pair to the reward model and collect its score (a number that scales with the preferability of the prompt-response relation). Use that number as a reward, or feedback signal, for the language model, an indication of how well the model is doing with its current parameters. Adjust the parameters of the language model via backpropagation so that its response to the prompt would have received a higher score. Finally, repeat this process over and over until the language model consistently produces high-scoring responses to prompts, responses that human evaluators would find preferable given their alignment criteria.
Just to be clear, the language model still engages in next-token prediction. However, its parameters are tweaked not to make it predict next words more and more accurately but so that its final outputs (as responses to prompts) achieve higher and higher scores from the reward model. This, of course, is why the process is called reinforcement learning: it algorithmically embodies the principle that behavior that was rewarded in the past is more likely to be repeated in the future.
This procedure is very similar to the way that machine learning algorithms are trained to play games like chess. However, rather than being trained to engage in certain actions (such as moving a knight) as a function of its current environment (understood as the current positions of all the other pieces), the machinic agent is trained to produce the next word as a function of the preceding words. In effect, it resides in and acts on a textual environment. And rather than being trained to win a game like chess or get a high score in a game like Pac-Man, it is trained to get a high score from the reward model for its response, and thereby do well when playing a particular kind of language game.
A language game—or, rather, a mode of language gamification—with ethical grounds, economic rewards, and existential risks.