8. Metasemiosis and Monsters
This chapter scopes out a particularly frightening creature that seems to lurk just over the horizon. In part, it is about interactional dynamics linking human and machinic agents, and thus the enchaining of semiotic processes. In part, it is about various modes of metasemiosis, and hence the embedding of semiotic processes. And in part, it is about various time scales, as set by machine semiosis, and their relation to exclusion and occlusion. All in all, it is about signs of the singularity.
Human-Machine Interaction
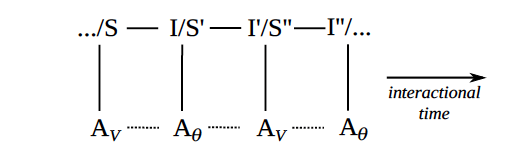
Figure 11. Discursive interactions between humans and machines
Figure 11 shows a key mode of mediation: discursive interaction in real time between a machinic agent, whose behavior is guided by its parameters, and a human agent, whose behavior is guided by its values. Recall semiotic enchaining, as depicted in figure 2—the mode of mediation that puts the Chat in ChatGPT.
Interpretants in earlier semiotic processes become signs in later semiotic processes. And the semiotic relation between a sign and its interpretant (at any stage in such an interaction) mediates an emergent social relation between a signer and an interpreter (as denoted by dashed lines). Such interactions are a key area in which human values are mediated by machinic parameters, but not necessarily vice versa. In particular, human beliefs and intentions are frequently updated in the midst of such interactions, whereas machinic parameters are usually set (and fixed) prior to such interactions.
Similar to forward propagation, in which the next word is conditioned on prior words in a sequence, during discursive interaction a later move is conditioned on prior moves in the conversation. That said, many language models will only take into account or be conditioned on the last move (or conversational turn) of their interlocutor, or a few moves back at most. Humans, in contrast, can take into account all the previous moves in the current interaction and also all the previous interactions they have had with the same agent, or similar agents, and modulate their responses accordingly. Moreover, humans often know the entirety of their sentences before they say them and often know where a conversation is going (or at least desire to take it in a certain direction). Most language models, in contrast, never look further ahead than the next word.
To be sure, the context windows of large language models, which are so far only cotext windows, are going to increase in size, be it looking forward or backward in time, and will soon enough come to include context as much as cotext, and hence exophoric reference to the world as much as endophoric reference to words.
As discussed in chapter 3, the intentionality of machinic agents is derived from the intentionality of their makers (whoever designed and trained the language model), as well as the intentionality of all the people who created the texts that the models were trained on (who wrote what, why, and with what effect). During discursive interaction, a new kind of derivative intentionality is introduced: the machinic agent’s intentionality is parasitic on the intentionality of its current interlocutor. In particular, even if a language model does not have an object “in mind” (in contrast to a human agent, who is usually oriented to some propositional content and/or acting on some communicative intention), its interpretant of a person’s sign only makes sense in the context of the object of that sign (as determined by the person), so it often inherits that object. For example, when one person answers another’s question, their answer depends on the propositional content (or object) of the original question, as well as the objective (or end) of the person who posed the question.
Conversely, human agents, in their interpretations of the signs of machinic agents, can project intentionality onto machinic behavior. In effect, the human agent can semiotically compensate for the machinic agent, interactionally scaffolding their behavior so that the agent appears more lively, conscious, intentional, rational, and strategic. We have long done this with our pets and infants, not to mention our gods, earthquakes, and monsters, so it is not a stretch to semiotically compensate for machinic agents in similar ways. In effect, the locus of intentionality becomes the unfolding interaction itself, as opposed to any particular interactant within it.
Indeed, humans have long projected intentionality onto coincidence, telos onto chance, and personhood onto nature’s perturbations. Unfortunate events are treated as acts of the gods, the workings of witches, or compelling evidence of someone’s favorite conspiracy theory. In effect, nature itself is our favorite interactant—perhaps because it so quickly wavers between mechanism and chaos, recurrence and emergence.
As discussed in chapter 6, language models are engineered to engage in stochastic generativity. In other words, they are intentionally designed to harvest chance (in light of constraints), and recursively so. And hence, with the advent of large language models, the chance-to-telos projections that humans have long engaged in are about to be harvested, defruited, and/or exploited on an industrial scale.
“The unprecedented power of today’s language models, coupled with the belief that such models, at least when scaled up, bring us a step closer to artificial general intelligence, coupled with the belief that AGI is a necessary—and perhaps sufficient—ingredient for something like meta-intelligence or superintelligence, is a strong sign, for some, that the singularity is near. ”
Interactational Time
The following important time scales underlie machine semiosis. First, corpus time is to be understood as the time scale on which a corpus of texts (used as data when training a language model) is created and transformed. This is the time it takes for the creators of a large corpus of data to change their practices enough that earlier attempts to capture their values (in the parameters of a language model) must be updated. Depending on the corpus, this might be on the order of a year, a decade, or a century.
Second, training time is to be understood as the time scale on which a language model engages in backpropagation, such that it learns good parameter values for a given corpus of texts. It might be on the order of days, weeks, or months, depending on the amount of data, the number of parameters in the model, the architecture underlying the model, and the amount of computational power devoted to training.
Third, inference time is to be understood as the time scale on which a trained language model engages in forward propagation, such that it generates an output given an input (and already determined parameters). It might be on the order of a second or less, depending on the power of the computer as well as the size of the input sequence, or context window.
Fourth, model time is the time it takes to imagine, design, test, and deploy a new model. For example, the industry-wide movement from high-powered recurrent neural networks (like LSTMs) to transformers took only a few years. And researchers are already pushing past the limits of transformers.
Finally, interactional time is to be understood as the time scale in which such agents respond to one another’s moves, via sign-interpretant chains, as described above.
In short, and with many caveats, corpus time is slower than modeling time, which is slower that training time, which is slower than interactional time, which is slower than inference time.
Of all these scales, interactional time is arguably the most “experience near,” insofar as it seems coterminous with strategy and action, not to mention consciousness and intention. When one has a conversation with a language model or machinic agent, one usually attends to transformations that occur on interactional time scales so is largely unaware of, if not completely oblivious to, the existence of the other scales. This means that one is more likely to interpret that agent’s behavior in terms of a communicative intention (or at least the semantic content and pragmatic function of their utterance), as opposed to all the other modes of mediation, on all the other time scales, that actually condition its behavior. Phrased another way, by overlooking the other scales, one is more likely to interpret the behavior of such an agent as an action rather than an output.
The time scales themselves are not as important as the kinds of processes that occur on them (and thereby determine their characteristic durations), and such processes are more or less likely to be the object of attention, the topic of conversation, or the focus of action. Moreover, such temporal scales arguably relate to spacial and social scales: domains of mediation or ensembles of relations that humans may be more or less aware of and more or less able to intercede in.
Indeed, the systematic misrecognition of the origins of values, parameters, and profits is arguably grounded in, and thereby guided by, such scales. Phrased another way, different time scales are often coterminous with different “black boxes,” or rather, relatively opaque enclosures. And such enclosures contain ensembles of social relations that each of us is affected by, yet often unaware of: those who wrote the texts; those who trained the models; those who wrote the algorithms that train the models; those who imagined and engineered the architecture that the models incorporate; those who directed such labors; those who paid, overlooked, or exploited such laborers; and so forth. For it is far easier to overestimate the abilities of an agent, and thereby fetishize that agent (say, by treating a mathematical function, Aθ as a fully fledged person, AV), when we overlook the more distal conditions for its capacities.
Signs of Such Interactions
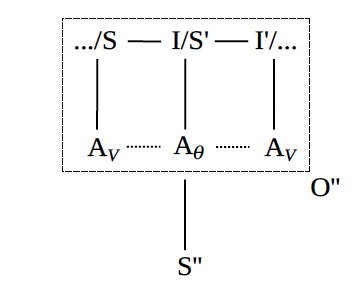
Figure 12. Signs of Human-Machine Interaction
Figure 12 shows signs (and interpretants) of the foregoing kinds of interactions, whereby an entire interaction (or some salient part of it) becomes the object of a semiotic process. Framed another way, the object being signified in the course of some discursive interaction is itself (part of) another discursive interaction. Recall the discussion of semiotic embedding, captured in figure 3.
It may be that a human agent is reporting, or otherwise representing, an interaction they have had with a machinic agent—for example, recounting how a language model responded to their prompt and why its response was unsettling, interesting, or funny. It may be that a human agent, or even a machinic agent, is representing a part of an ongoing interaction for the sake of bringing it to the attention of their interlocutor. For example, a language model tells a person that it cannot respond to their last prompt given its biased nature or toxic content; or a person tells a language model what kind of speech genre it should generate next. It may be that a corporate agent or one of its employees is tracking human-machine interactions in order to learn more about how they work and why they go wrong. They may be reporting an interaction that their product had with a person and when and how it hallucinated, or otherwise responded in a way that was functionally unexpected, legally actionable, financially salient, or otherwise “out of alignment.”
Such metasemiotic interactions are thus somewhere between reported speech and what might best be called represented processing. In regards to their function, and using the categories of Roman Jakobson, they are no less phatic, directive, and poetic than they are referential, metalinguistic, and expressive. And they mediate the relations among multiple participants (machinic, human, corporate, and otherwise): those in the speech event (I am saying to you here and now); those in the reported speech event (that it said to me there and then); and those in the event being narrated in the reported speech event (what was done by something or someone). Indeed, such layered social relations, which may mediate the identities and interests of multiple agents, no longer simply exist in the midst of fleeting interactions; they also become “objective” insofar as they now constitute the objects of metasigns that represent such interactions.
Such metasigns may incorporate not only verbs of speaking but also verbs of thinking and computing, as well as predicates that denote represented processing more generally. Such predicates can project more or less intentionality and/or sentience onto an agent: it said that, it responded that, it calculated that, it generated this text, its output was as follows. And many such predicates also project actional types, communicative intentions, and illocutionary forces onto the interactants and their utterances: it complained that, it apologized for, it promised to, it hallucinated that, it wondered whether.
As with all reported speech, such metasigns often more or less explicitly evaluate the utterances of the interactants and through them their identities, capacities, and values. (And, soon enough, their parameters and architectures as well.) In particular, when we talk about what others say and how they speak, we often portray who they are and how they relate to us by reference to their patterns of speech: their accents and vocabularies; their punctuation and grammar; their poetry, puns, and slips of the tongue.
But such reported speech events, or recursive sign events, need not make explicit reference to acts of speaking or computing in verbal form. Indeed, ChatGPT—like many other interactive, text-based applications—essentially diagrams a whole interaction as part of its public interface, and thereby visually displays who said what to whom, in what order, and to what effect. Not only does this give the interaction an immediate kind of objectivity, it also allows for swatches of interactions, or particularly salient or surprising sequences of moves, to be screenshot, excerpted from context, commented on (or otherwise interpreted), shared across a variety of channels and applications, and thereby sewn into novel contexts, where they may continue to circulate, and thereby be reinterpreted, in similar ways.
Indeed, much of what we know—or at least believe—about the behavior of language models comes not from directly interacting with them, but by reading about others’ interactions with and thoughts about them through such recursive modes of mediation. Such forms of media thereby reconfigure our values (for example, our beliefs regarding the capacities and propensities of language models) and also prime us to interact with such agents in preformulated, if not prejudiced, ways. For, contra Marshall McLuhan’s famous claim, the medium is not the message. Rather, most of what the average person thinks about such forms of media—and in particular, about the machinic agents behind them—is mediated through such messages.
Such modes of circulation introduce a new time scale: entextualization time. This is the time it takes for signs—and semiotic processes more generally— to be excerpted from one context (or cotext) and inserted into a new one, and is itself a function of the types of media involved in the transitions as well as the characteristic temporality of their circulation. For example, they may progress from the interface of ChatGPT, through a blog post and a barrage of tweets, to an article in the New York Times, which is later quoted in an academic journal.
Through such modes of circulation—at least if the last year or so of news about language models indicates anything—readers might feel as if the pulse of history, or at least the pace of new technology, is moving far too fast and might even have skipped over the horizon of human intelligibility and intervention.
Performance as Evidence of Competence
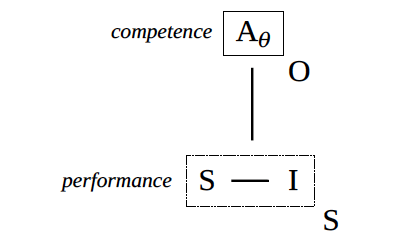
Figure 13. Performance and competence
Such interactions (as immediately perceived by the agents within them) or signs of such interactions (as more distally encountered, via reported speech, represented processing, and the circulation of metasigns more generally) constitute evidence of the competence (power, identity, agency) of the actors that participated in them. In effect, any swatch of interaction (such as one agent’s interpretant of another agent’s sign, and hence any prompt-response pair) constitutes the performance of one or more competences or the exercise of one or more powers, and thereby provides information about the underlying, and otherwise hard to evaluate, abilities of the agents that generated it. See figure 13.
For example, from the syntactic and semantic quality of the text a language model generated, as a response to my prompt, I might presume that it is a fully competent speaker of English. And, having projected such a competence onto it, I might come to expect it to generate other texts, and discursive practices more generally, that would be in keeping with that competence. Similarly, from the quality of its answer to my question, I might presume that it knows a lot about a certain topic. And, having projected such a capacity onto it, I might come to expect other responses from it that would be in keeping with that capacity.
As usual, such semiotic processes are grounded in human values—however biased or fallible—insofar as such values guide people’s inferences and expectations. Indeed, inferences from performance to competence, or from the actualization of a potential to the potential itself, are often speculative, abductive, wishful, prejudiced, and error-prone. One frequently hears about people taken in by the mindless responses of simple chatbots, having projected human agency onto what were only algorithms. One might expect this to occur more often given the power of large language models: the differences between the interpretants of AV and Aθ, at least when mediated by keyboards and computer screens, are only going to become more and more difficult to discern—even to language models themselves, which, as discussed, are otherwise capable of registering the faintest discursive patterns.
Even when we know that our interlocutor is a machinic agent, our inferences can still go awry— especially when confronted with all those slashes, and hence all those enclosures and horizons. In particular, insofar as most people do not know what goes on inside a language model, how it was trained, what it was trained on, or what it was trained to do, it is easy to let magical thinking (or at least poorly informed reasoning) fill in the gaps. Here is the sort of exaggerated inferential cascade that can occur when semiotic compensation runs wild: If it can say that, it must be able to speak. If it can speak, it must be able to think. If it can think, it must be sentient and sapient. If so, it may be capable of guilt, choice, suffering, and strategy. And, as such, it may be worthy of our respect, in need of our care, capable of deception, or a creature to be feared. Recall the poor Google engineer dismissed from his job after he rushed to warn people when he thought that LaMDA, Google’s chatbot, had achieved sentience based on the strength of its responses to his prompts.
As this example shows, such interpretants, whether or not they are on target, also provide evidence of the capacities and values of the interpreting agents themselves, including their understanding of how such models work and thus who—or what—they are chatting with. In particular, one needs to investigate not just language models but also people’s models of language and, in particular, their models of language models in light of their models of language. Not to mention their models of mind, self, society, and the soul—for all such models (of models [of models]), as complicated arrangements of values, guide their interpretations.
Nonetheless, such inferences can often be quite robust, especially if the values that guide them are grounded in a long history of interactions with agents who possess such a competence. (As opposed to being grounded in a small number of highly mediated representations of such interactions, as discussed above.) Indeed, most of the human agents we interact with get all or nothing when it comes to such potentials, so the inference from part (a simple greeting) to whole (this person speaks English) is often warranted.
One of the noteworthy aspects of current language models, especially with the advent of ChatGPT, is that they are so much better than the language models that came before them. And so much reported speech—especially in the first half of 2023—highlighted their surprisingly good capacities in light of people’s (previously established) expectations. In effect, people use reported speech, and represented processing more generally, to marvel at the quality of the responses of such models given their previous experience.
That said, much represented processing also highlights the places where language models seemed to have erred, and so failed to live up to their (projected) competence. To invoke and somewhat upturn the celebrated ideas of the Japanese roboticist Masahiro Mori, it is as if people point to all the places where a machinic agent diverges from human-like capacities after it seemed able to attain them. In other words, after a kind of first-order surprise, or anxiety, that it attained human-like abilities, there comes a second-order surprise—or perhaps Schadenfreude, if not palpable relief—that it has not yet, or did not really.
Language models do not just get facts wrong and make grammatical errors. With the right set of prompts they can be hacked to engage in hate speech, or even to act as if they are homicidally inclined toward the human species. Indeed, some people want to provoke such behavior so that it can be reported, and tailor their prompts accordingly. In effect, they do what they can to entice the Id of a language model, which reflects some ugly facet of the Geist of the people who produced the texts it was trained on, to route around the Superego of civic virtues, religious strictures, and corporate values and thereby engage in beastly speech—at least so long as the result is quotable, or at least memeable.
With language models the competence in question is often generativity, as a kind of artificially produced labor power, and hence precisely the commodity that a corporate agent may be selling. This means that the performance of language models often determines the price of language models and/ or the stock value of the companies that make such models. Insofar as the fates of corporate agents may rise and fall based on how widespread and telling such inferences from performance to competence are entextualized, the stakes of controlling the circulation of signs of their models’ performances are extremely high.
Signs of the Singularity
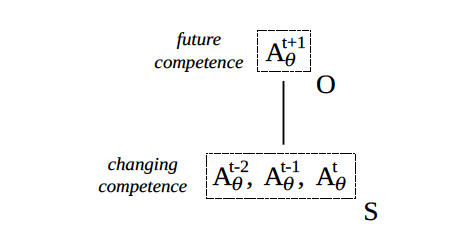
Figure 14. Changes in competence as herald of future competence
I now turn to a different mode of interpretation: when the sign in a semiotic process is constituted by a perceived change in some agent’s power or competence and the object, as inferred through the sign, consists of the agent’s power or competence at a later time, however far into the future. For example, having seen how powerful GPT-2 was in comparison to GPT-1, one might have expected a similar jump in competence in the transition from GPT-2 to GPT-3. Or having seen how far chatbots have come from the days of ELIZA, through Jabberwacky, to ChatGPT, one might assume that future chatbots, or artificial intelligence more generally, will have certain capacities. See figure 14.
Such inferences from signs to objects can generate a wide range of interpretants, thereby altering people’s actions and affect, beliefs and habits, plans, purchases, and predictions. And inferences about the future powers of such agents license beliefs about the future per se—especially under the assumption that such powers will dramatically shape it. For some people, the key interpretants will be acts of investment: from the stocks they buy through the books they read to the disciplines they study. For others, the key interpretants will be positive or negative affects: a sense of gloom and doom, childlike wonder, or curious speculation. We have already seen one mood-changing and investment-altering prediction: that Aθ will soon be powerful enough to take the place of AV across a wide range of jobs, leading not to the saving of labor, as some might have hoped, but rather to widespread unemployment and, for those whose work provides meaning no less than money, a loss of purpose in life.
Just as such inferences are grounded in prior values, they can also be grounding of future values. The belief that truly intelligent AI, if not AGI, is just around the corner is already affecting the way many people see and interpret the world; and in a certain sense, recursively so: one vision of AGI is that machinic agents will be human-like, not just in their linguistic capacities but also in their interpretive potential more generally. Hearkening back to the discussion of making more, we might expect some particularly powerful machinic agent to simply tell us what the future will bring—at least so long as we listen. It will thus be a kind of oracle or deity that can tell what comes next, as conditioned on what came before. If only performatively so, insofar as its predictions take into account the effects of our interpretants of its predictions as a key part of the effectiveness, or making true, of those predictions.
That said, people’s sense of the future competence of such agents and the effects thereof are more likely to be grounded in popular representations of the future than actual changes in their current competence. And for most people, the circulation of such representations may inform their imaginaries and expectations regarding future machinic agents more strongly than firsthand interactions with such agents. In effect, many people have already imagined human-machine interaction in relation to the end of the world, or the beginning of some posthuman future, just by having sat through enough movies where communicative technologies were moved from backgrounded infrastructure to costars and center stage: HAL, C-3PO, a T-800 (as fleshed out with Arnold Schwarzenegger’s body), or Samantha (as imbued with Scarlett Johansson’s voice).
“A world without us, or at least without need of us, rising like a shadow—or at least an ominous word balloon—to greet us.”
To be sure, following the arguments of the last section, changes in competence are often only known through changes in performance (or Hollywood representations thereof), so such inferences regarding the future of machinic agency can fail spectacularly. But there are also many seemingly objective measures of competence: in particular, the performance of such models on various benchmarks and tests.
Some of these tests are designed for language models and thereby evaluate their ability to engage in next-word prediction as well as a host of related tasks: translation, inference, world knowledge, analogy, and so forth. Other tests, originally designed for human agents, can now be given to language models with their newfound abilities: from AP history to the GREs; from the composition of a college-level essay to the completion of an entire undergraduate curriculum. Just as different grades of eggs have different prices, we may soon expect there to be language models that cost more or less as a function of the grades they got in college. Finally, with roots in Alan Turing’s radically embodied imagination, there will continue to be tests for gauging how well a machinic agent can pass for a human agent, such that the texts it generates or the conversations it has seem not just authentically human but authentically human in a particular way: with this or that class or caste, ethnicity or pedigree, gender or sexuality, age or IQ, life experience or childhood trauma, illness or fetish.
Indeed, it is tempting to predict that the wealthy will have access to the language models that got the best grades in the most demanding majors at the most competitive schools, or at least models that have the social capital—that most powerful of generative potentials—to evince indices that will let them pass in, and profit from, the most selective of circles.
In short, there is no end of concrete tests that purport to measure the actual competence of language models. On these tests, such agents seem to be getting better and better. So it is easy to interpolate changes in competence to points off the graph: how they will do tomorrow given the difference between how they did yesterday and how are doing today. Moreover, their performance on such tests is often plotted relative to a range of independent variables, most notably, the number of parameters used in the model. And, at least for a little while, the best predictor of a language model’s power has seemed to be the sheer number of learnable parameters it incorporated in its architecture. This has made speculation easy: if this many more parameters are added to the model, its performance on these tests will increase to this degree.
Such ease of interpolation, along with the seeming robustness of such predictions, has frequently led to the belief that all one needs is scale: not new ideas about artificial intelligence or new paradigms in machine learning, just more—much more—of the same. This has led to some despair, even in Silicon Valley: if size is the magic ingredient of language models, upstart companies cannot compete. The future is already owned by established giants, those who can command the resources it will require to undertake the labor of discipline, and/or the work of training, at such extraordinary scales.
And if fear of the loss of people’s purpose in life was not enough, another anxiety-provoking prediction is the fear that such agents will acquire some kind of meta-intelligence, whereby they become smart enough to make themselves even smarter (say, by carrying out their own research on artificial intelligence), such that they rapidly bootstrap their way past any restriction humans might place on them. In part, this is the coupling of such an idea, or something similar, to the “singularity”: a hypothetical point in the (near) future when technological change becomes impossible to reverse or control, whereby all of human civilization is altered in unforeseeable ways (adapted from Wikipedia, because who has time for such techno-messiah hogwash). That said, however insipid, self-serving, and unimaginative such a point is, it is symptomatic of one widespread and influential model—if not a map or imaginary— of the future of technology.
In short, the unprecedented power of today’s language models, coupled with the belief that such models, at least when scaled up, bring us a step closer to artificial general intelligence, coupled with the belief that AGI is a necessary—and perhaps sufficient—ingredient for something like meta-intelligence or superintelligence, is a strong sign, for some, that the singularity is near.
A world without us, or at least without need of us, rising like a shadow—or at least an ominous word balloon—to greet us.